Data Quality vs Data Observability
Data observability aims at allowing data teams to monitor and troubleshoot data systems and pipelines. Data observability capabilities can be broken down into the following pillars:
Freshness: measures the timeliness and frequency of data updates and pinpoints gaps in data updates, making sure that pipelines are functioning optimally.
Distribution: monitors that data is distributed successfully along data pipelines by cross-checking values between source and target systems.
Volume: measures the quantity and completeness of data processed through various processes and pipelines to ensure that the amount of data received is consistent with historical patterns.
Schema: verifies schema stability, and identifies issues and discrepancies across systems as change in structure occurs.
Lineage: tracks the journey of data from its source to its destination, traces the impact of changes on data and explains where the data came from in case of issues.
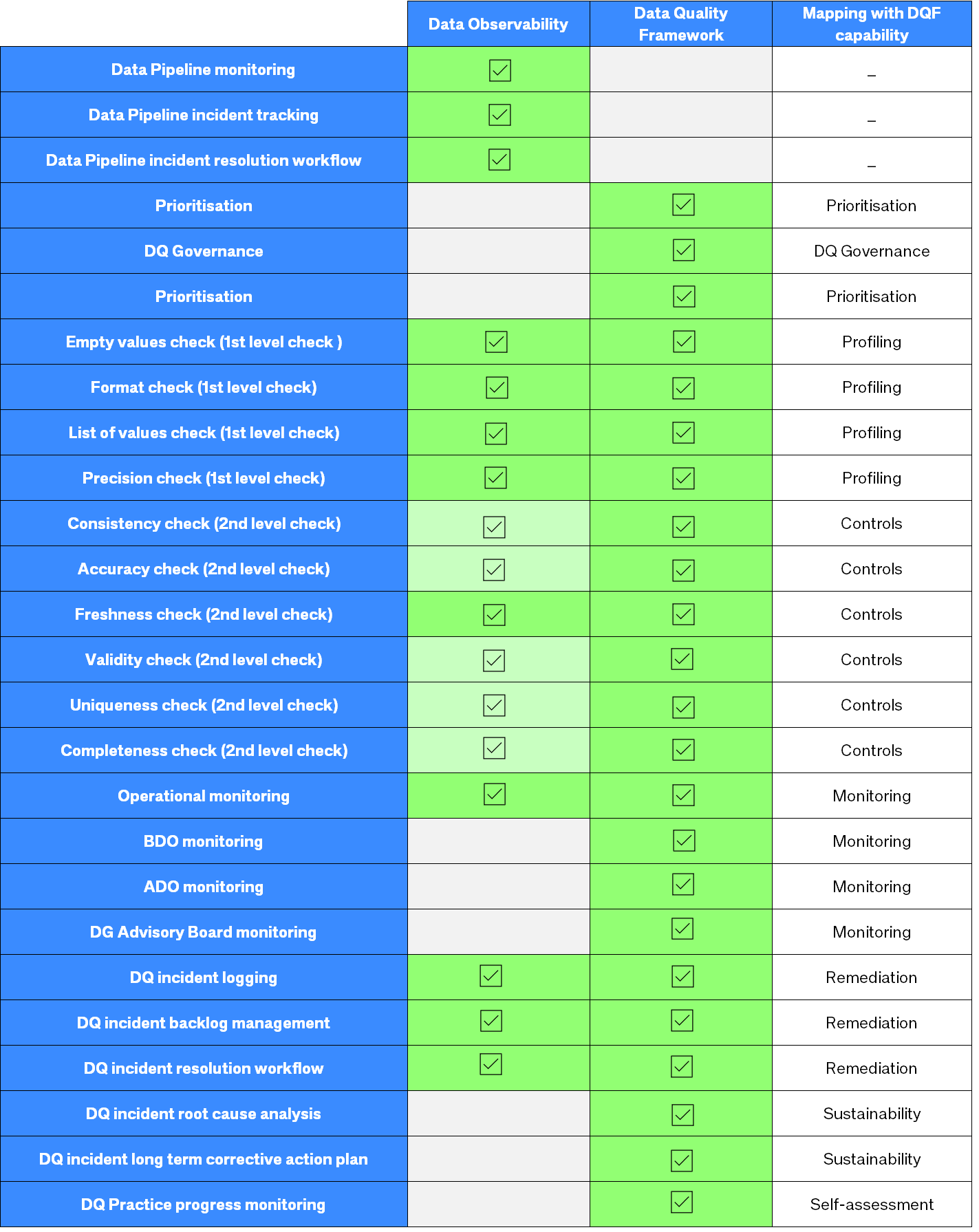
While Data Observability focuses on data operations such as ensuring the timely arrival of data in the correct format, first level checks or data profiling and to some extent row-level validation, Data Quality encompasses processes and tools to execute detailed assessment of data against specific rules or conditions to verify its accuracy and ensure compliance with business rules.
The following table presents a high level comparison between Data Observability and the scope of the Data Quality Framework: